Rank教程: 10-Learning to Rank Aggregation
欢迎转载,作者:Ling,注明出处:Rank教程: 10-Learning to Rank Aggregation 本文不打算详细介绍每个算法,具体算法细节可以看Paper,但是本文会大…
93
文章
73768
评论
1
邻居
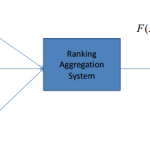
欢迎转载,作者:Ling,注明出处:Rank教程: 10-Learning to Rank Aggregation 本文不打算详细介绍每个算法,具体算法细节可以看Paper,但是本文会大…
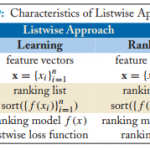
欢迎转载,作者:Ling,注明出处:Rank教程: 09-Learning to Rank Listwise 本文不打算详细介绍每个算法,具体算法细节可以看Paper,但是本文会大致给出…
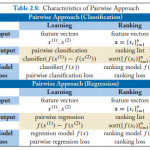
欢迎转载,作者:Ling,注明出处:Rank教程: 08-Learning to Rank Pairwise 本文不打算详细介绍每个算法,具体算法细节可以看Paper,但是本文会大致给出…
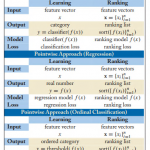
欢迎转载,作者:Ling,注明出处:Rank教程: 07-Learning to Rank Pointwise 本文不打算详细介绍每个算法,具体算法细节可以看Paper,但是本文会大致给…
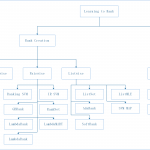
欢迎转载,作者:Ling,注明出处:Rank教程: 06-Learning to Rank 概述 机器学习排序:Learning to Rank 之前考虑的特征种类非常少,当特征数目增多…
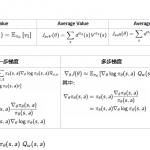
欢迎转载,作者:Ling,注明出处:强化学习教程: 10-强化学习公式大全 回报: 值函数:Value Function 策略函数:Policy Function 马尔科夫奖励过程的贝尔…
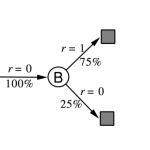
欢迎转载,作者:Ling,注明出处:强化学习教程: 09-Exploration and Exploitation 本章主要讲解了强化学习中一个基本的权衡问题,就是探索与开发的问题,这是…
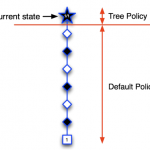
欢迎转载,作者:Ling,注明出处:强化学习教程: 08-Model-Based RL Dyna and Tree Search 上一章是从经验(Experience)中学策略(Poli…
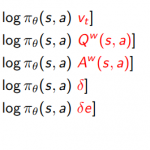
欢迎转载,作者:Ling,注明出处:强化学习教程: 07-Model-Free Policy Gradient and Actor-Critic 前面所介绍的都是Value-Based …
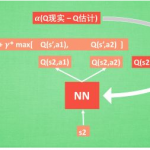
欢迎转载,作者:Ling,注明出处:强化学习教程: 06-Model-Free Control, DQN 本章主要介绍 DQN 大规模强化学习: 到目前为止,我们的value funct…
 默认
默认