深度学习:前沿技术-ALBert
欢迎转载,作者:Ling,注明出处:深度学习:前沿技术-ALBert 简介 ALBert (A lite BERT)ALBert (A lite BERT) 是一种通过减少BERT训练参数,从而使得在…
93
文章
72078
评论
1
邻居

欢迎转载,作者:Ling,注明出处:深度学习:前沿技术-ALBert 简介 ALBert (A lite BERT)ALBert (A lite BERT) 是一种通过减少BERT训练参数,从而使得在…

欢迎转载,作者:Ling,注明出处:深度学习:前沿技术-DistilBERT 简介 DistilBERT (Distilled version of BERT) 是一种压缩BERT模型的方法,它可以在…

欢迎转载,作者:Ling,注明出处:深度学习:前沿技术-RoBERTa 简介 RoBERTa (A Robustly Optimized BERT Pretraining Approach):提出了一…

欢迎转载,作者:Ling,注明出处:深度学习:前沿技术-GPT 1 & 2 GPT 1 定义 GPT是“Generative Pre-Training”的简称,从名字看其含义是指的生成式的预训…

欢迎转载,作者:Ling,注明出处:深度学习:前沿技术-XLNet 简介 XLNet通过改进深度学习在自然语言处理中典型的两阶段学习的预训练语言模型阶段(Pretrained),来提高深度学习在自然语…

欢迎转载,作者:Ling,注明出处:深度学习:前沿技术-Tranformer-XL 简介 Transformer-XL架构在vanilla Transformer的基础上引入了两点创新:循环机制(Re…
欢迎转载,作者:Ling,注明出处:深度学习:前沿技术-Vanilla Transformer 简介 Al-Rfou等人基于Transformer提出的一种训练语言模型的方法,来根据之前的字符预测片段…
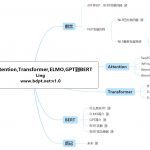
欢迎转载,作者:Ling,注明出处:前沿技术-从Attention,Transformer,ELMO,GPT到BERT 1 前言 1.1 2018NLP:BERT惊艳四座 2018年一篇论文 &ldq…
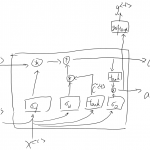
欢迎转载,作者:Ling,注明出处:深度学习:原理简明教程20-深度学习:GRU和LSTM 有了Simple RNN为什么还需要GRU和LSTM: 因为存在梯度消失问题!!!层次太深!!…
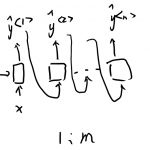
欢迎转载,作者:Ling,注明出处:深度学习:原理简明教程19-深度学习:序列模型与RNN 什么是Neural Network(NN): 神经网络训练输出是没有位置信息的。所以需要专门的…
 默认
默认