Ling APP:批量OCR及双层PDF制作工具BDO(Batch Document OCR)
欢迎转载,作者:Ling,注明出处:Ling APP:批量OCR及双层PDF制作工具BDO(Batch Document OCR)
由于写东西有的时候希望可以将扫描版书中内容复制出来,所以需要制作双层PDF,无奈现在工具要么识别慢,要么收费极其高,于是我自己做了一个软件,可以批量,多线程,快速OCR PDF,保存成双层PDF文件。
双层PDF:如果还不知道什么是双层PDF是什么可以看看老马的帖子:
目前期刊、论文、标准通常以PDF格式发布,这些PDF可以分为以下几种:
一、扫描版PDF
这种PDF直接把扫描图像打包成PDF,又称“图像版PDF”。
好处是:
1、完整保留原始格式与内容,看到的内容与原文是一样的。
2、制作容易、来源广泛。
坏处是:
1、如果是纯图像版,不能进行检索、复制,用起来会很麻烦。
2、扫描质量参差不齐,效果如何要看运气。
3、制作技术参差不齐,很多时候要进行二次处理,包括背景透明、OCR等。
4、放大、打印的时候会有锯齿。
二、双层PDF版
这种PDF是在扫描版PDF的基础上,进行OCR(光学字符识别,即用软件把扫描图像识别成文字),然后把OCR出来的文字做成透明文字层,蒙到原始扫描图像层上,所以称为“双层PDF”。与纯扫描版PDF相比,这种PDF可以进行文字检索、复制、导出,因此又被称为“可检索扫描PDF”。目前网上流传的大部分科技文献都是这种类型的PDF。
好处是:
1、眼睛看到的是扫描图像层,因此只要原文没有错,看到的东西就不会有错。
2、可以用眼睛看不见的隐藏文字层进行搜索、复制、导出。
坏处是:
1、文件长度略大,毕竟需要存储图像、文字信息。
2、搜索、复制、导出结果完全依赖于OCR结果。我个人感觉,科技文献的OCR效果都不会太好,所以眼睛看到有某个词,搜索的时候却没有;或者眼睛看到的内容是正确的,想引用的时候却发现复制、粘贴出来的内容错字连篇,也没啥好惊讶的——全是OCR惹的祸,机器毕竟没有人聪明。
3、对某些字体、符号可能会出现位置不准的情况,所以用鼠标选择的时候,选中区域可能会与眼睛看到的文字位置不一致,这也是判断双层PDF的一个重要特征。
三、文字PDF
这种PDF是用原文直接转换出来的,而不是扫描出来的,因此与上面两种类型最根本性的区别是没有扫描图像。
好处:
1、文件长度相对比较小。
2、放大、打印都很清晰,看不到锯齿。通常最简单的用肉眼区别扫描版PDF与文字版PDF的办法就是放大到400%以上,看文字边缘有没有锯齿。
3、只要原文没有错,复制、搜索、导出就不会有错。尤其是某些比较细小的符号、文字,OCR结果多半胡说八道,文字版则不存在这样的问题。
坏处:
可遇不可求,毕竟要有原文才能制作出来。以标准为例,大概只有标准的起草、发行、出版等拥有原始电子文稿的单位才能出版文字版PDF,其他人拿到手的就是出版后的纸质文档,想电子化就只能靠扫描了。
当然也有个人制作的精美文字版,最出名的可能是Ken777用校对后的OCR文本制作的“精确版面还原”PDF,可以做到PDF与原版纸质书的页数、每页行数、每行字数一致,可以直接引用。
我个人也是比较推崇双层PDF,最主要的好处是:
1)可以搜索
2)可以复制,用于做笔记,写博客,做摘录
3)。。。自己发挥想象
目前制作双层PDF主要问题:
OCR太慢(其实准确率还是可以接受的),一本书得花个把小时才能搞定,效率低得惊人。
于是乎我自己开发了个自用软件,直接一行命令就可以批量进行识别转换,无需人工干预,准确率个人觉得和abbyy不相上下,最关键是,N多本扫描版pdf,一行命令,多线程批量全部转成双层pdf。速度比原来提高N倍。
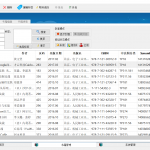
下面给大家看看效果:
转换后的(2线程,150dpi,28本PDF,用了2个多小时,机器更好的话,开更多线程更快):

对比图:
一本书中拷贝出文字的效果:
一本书同时生成txt和双层pdf的效果:
中英混合的效果:
个人已经很满意了,当然准确率没法100%,可以通过后期进行精校准解决。
留言